AudioPen:让Ai帮你整理碎碎念,语音书面化的利器【元知识】
本期视频将分享我是如何通过AudioPen把语音转换为书面化的文字,并且自动保存到obsidian笔记中的。
这个工作流可以把日常的碎片时间利用起来,用语音写笔记。
视频地址:https://www.bilibili.com/video/BV19z421q7fy

这个工作流可以把日常的碎片时间利用起来,用语音写笔记。
视频地址:https://www.bilibili.com/video/BV19z421q7fy
虽然微信是坨,但是也是必装的一坨,所以好好利用这坨!
视频地址:https://www.bilibili.com/video/BV1R1421b73v
为什么很多人会纠结用notion还是obsidian?因为notion具有强大的在线功能,一旦使用场景超越了单设备,obsidian用户就不得不面临诸如“同步”、“发布”和“跨设备”的问题。
我使用obsidian三年有余,尝试了几乎所有同步方式,最终得出结论:目前现成的解决方法不可能得到完美体验(指对标原生在线的笔记应用,如notion)。
因此首先需要厘清自己的需求,再因地制宜去改造obsidian,这也是obsidian最大的优点:客制化潜力巨大(来源于它使用md格式文件和它繁荣的插件社区)。
比如我的工作流包括以下场景:
1. 在pc上使用obsidian客户端写笔记
2. 在手机上看b站视频、浏览器网页的时候想要分享我看的东西
3. 在手机上记录memos
4. 在手机上查看我的obsidian笔记库并编辑
其中最麻烦的事是如何在手机上得到良好体验,obsidian虽然有官方的app,但是体验不佳。而且在手机端进行复杂编辑还想要好体验本身就是一个伪命题(除非外接显示器和键盘),因此我选择使用网页(当然这里做出了妥协,即放弃了ob各种强大的功能,网页上只做简单的文字编辑),这样直接解决了跨平台的问题。
通过上面的分析后,拆解我的工作流来分析需求,可以得到三个版块
1. 同步
2. 信息输入
3. web发布
而obcsapi几乎完美的符合了我的需求,下面我将正式开始介绍obcsapi这个开源项目。
obcsapi是由中国obsidian用户恐咖兵糖开发的一款obsidian工具,其官方介绍如下:
基于 Obsidian S3 存储, CouchDb ,本地存储和WebDAV 的后端 API ,可借助 Obsidian 插件 Remotely-Save 插件,或者 Self-hosted LiveSync (ex:Obsidian-livesync) 插件 CouchDb 方式,保存消息到 Obsidian 库。或者支持本地文件夹的文本编辑器。特点
- 前端添加 Memos / 简答编辑 , 支持指令模式,有黑暗主题 ,是 PWA 应用
- 微信测试号 微信到 Obsidian
- 支持简悦 SimpRead Webook 裁剪网页文章
- 支持 fv悬浮球文字图片分享保存
- 静读天下 MoonReader 高亮标注 仿 ReadWise API
- 通用 http api
- 使用 Lua & Bash 拓展功能。用户可以处理任何请求
- WebDAV 服务
- 一个简易图床,附带命令行上传工具。
- 云函数 或者 Dokcer 部署
可以看到obcsapi的使用前提是需要自己部署,我个人是采用自租vps部署,当然也可以使用云函数+对象存储,Nas+内网穿透等方法。
它可以做到包括但不限于如下功能:

还有更多功能见文档Obcsapi使用说明
最后实际的使用效果见我的b站视频:Obcsapi:如何让obsidian和notion打擂台?【元知识】_哔哩哔哩_bilibili


参考资料:无需下载软件!网易云歌词下载&网站生成SRT字幕方法_哔哩哔哩_bilibili
简要总结:
F12 打开控制台,搜索 lrc 能找到 lyric?csrf_token=29d51bc21214a2b0039928c8dc704967 这种格式的网址,然后右键复制响应,把包含歌词的json文件粘贴到一个word文档内,搜索替换换行符 \n 为手动分页符(替换的高级功能中手动选择)
然后把格式化完成的歌词放到 .lrc 文件中
原文地址:[下载网易云音乐的双语歌词](https://umi.im/cloud-music-lrc/
==网易云音乐==是国内最好的音乐平台,歌曲丰富,而且很多外语歌都有双语歌词。但是==网易云音乐==不提供歌词下载,用手机客户端可以一键获取,但是获取到的歌词并非 LRC 格式的,而且文件名是纯数字,不方便用。
在 PC 端,可以通过一段 JS 脚本直接获取到双语的歌词。
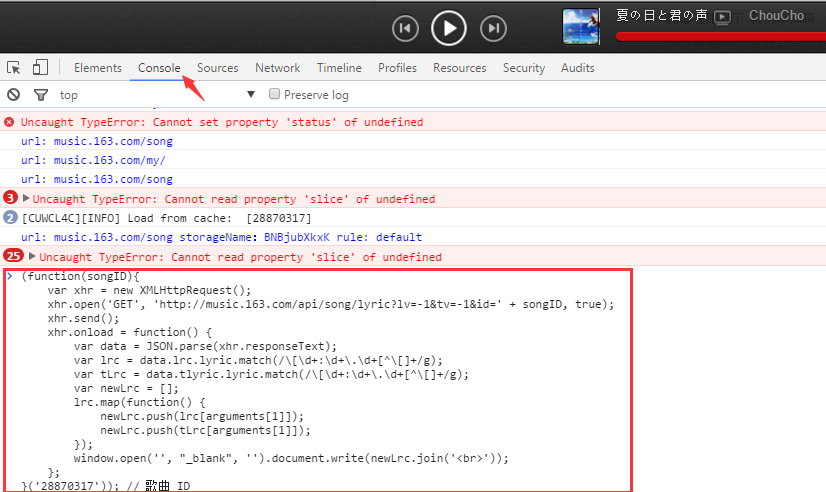
(function(songID){
var xhr = new XMLHttpRequest();
xhr.open('GET', 'http://music.163.com/api/song/lyric?lv=-1&tv=-1&id=' + songID, true);
xhr.send();
xhr.onload = function() {
var data = JSON.parse(xhr.responseText);
var lrc = data.lrc.lyric.match(/\[\d+:\d+\.\d+[^\[]+/g);
var tLrc = data.tlyric.lyric.match(/\[\d+:\d+\.\d+[^\[]+/g);
var newLrc = [];
lrc.map(function() {
newLrc.push(lrc[arguments[1]]);
newLrc.push(tLrc[arguments[1]]);
});
window.open('', "_blank", '').document.write(newLrc.join('<br>'));
};
}('28870317')); // 歌曲 ID
感谢 V2EX 用户 demo 贡献此脚本。
GitHub地址:anonymous/concat_163_music_lrc.js
https://blogs.qudange.top/p/2024-07-13-how-to-download-the-lyrics/
本文的实现方式受到chrome拓展ChatGPTBox的启发,原理是通过b站的api和cookie获得自动ai字幕,然后用大语言模型(LLM)来总结字幕,从而获得视频的总结。
此工具的功能是帮助用户快速总结视频内容,以提高信息获取的速度。诚然,b站自己也推出了ai总结功能,但是那个功能很不稳定,有时候对一个视频有详细而结构化的总结,有时却只能得到一句话的概括,即便LLM已经火了两三年了,b站仍没有在这块投入过多,因此只能自己动手,丰衣足食。
本工具的缺点:
1. 无法总结没有字幕的视频(但是像bibigpt和b站官方的ai总结有时候能总结没有字幕的视频,我怀疑是有其他途径获取字幕)
2. 对视频内容和音频内容非强相关的视频无效(例如一个ASMR催眠视频,如果只用声音来判断,可能整个视频都是没有意义的。我们期待在未来多模态的ai能解决这个问题)
3. 需要使用b站的cookie才能获取视频字幕,而cookie是动态变化的,因此需要cookie刷新机制,我的处理办法是使用cookiecloud(需要自己的服务器/托管在别人的服务器上)
https://api.bilibili.com/x/web-interface/view?bvid=%bidhttps://api.bilibili.com/x/player/v2?cid=%cid&bvid=%bid以视频【游戏试玩】杀戮尖塔+娃娃机=抓抓地牢?游戏实况 为例,如果采用安卓端国内版bilibili应用分享链接,得到的链接为【【游戏试玩】杀戮尖塔+娃娃机=抓抓地牢?-哔哩哔哩】 https://b23.tv/jpcq7rz
(隐藏的第一步为获取最新的cookie,因为实现方法不唯一,在下一章节介绍)
因此第一步是要从文字中提取出链接,一般采用正则
(https?|ftp|file)://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]
得到结果为https://b23.tv/jpcq7rz,然后我们需要将短链接转为长链接,最简单的办法就是使用浏览器的重定向功能,最终将得到https://www.bilibili.com/video/BV1DC411J7Wy/
然后使用正则提取出bid,正则如下:
BV([^/?]+)
即得到BV1DC411J7Wy
然后执行http get https://api.bilibili.com/x/web-interface/view?bvid=BV1DC411J7Wy 可以获取一个json文件,需要从中提取cid,因此执行两次正则
正则1(先匹配cid):
"cid":(\d+)
得到:"cid":1524209082
正则2(提取cid的值):
(\d+)
得到1524209082
然后获取字幕url,执行http get https://api.bilibili.com/x/player/v2?cid=1524209082&bvid=BV1DC411J7Wy
注意,header中需要加入cookie,如
User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36
Cookie:%cookieString
然后会获得一个包含键为subtitle_url的json文件(前提是视频有字幕),因此这里为了避免不存在字幕产生的误会,需要做一个有无的判断
用正则进行匹配
//[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]
如果不匹配,则提示此视频无字幕,若满足则进行下一步
对subtitle_url执行http get,获得json,提取键content
然后把content的内容http post给LLM
headers:
Authorization: Bearer %api_key
body:
{
"model": "%llm_model",
"messages": [
{
"role": "user",
"content": "用尽量简练的语言,采用markdown语法书写(不要用代码块包裹),联系视频标题,对视频进行内容摘要,同时仍要保留重要细节和标题信息,视频标题为:%bili_name,字幕内容为:%subtitle"
}
],
"use_search": true,
"stream": false
}
然后就能获得ai总结的内容了
我选择使用开源项目CookieCloud实现cookie的同步
变量解释:
– %cookiecloud_url:cookiecloud服务器域名,例如:https://cookiecloud.25wz.cn/,注意,结尾没有/
– %cookiecloud_uuid:见cookiecloud插件文档
– %cookiecloud_key:见cookiecloud插件文档
步骤详解:
执行http get %cookiecloud_url/get/%cookiecloud_uuid
请求的body如下:
password%cookiecloud_key
这一步会获得解码后的json,包括cookie和localdata
然后通过JavaScriptlet来格式化cookie
var jsonData = JSON.parse(local('%http_data'));
var cookies = jsonData.cookie_data[".bilibili.com"];
var result = [];
for (var i = 0; i < cookies.length; i++) {
var name = cookies[i].name;
var value = cookies[i].value;
result.push(name + "=" + value);
}
// 将结果存储在Tasker的全局变量中
setGlobal('cookieString', result.join(';'));
注:其实这一步理论上只需要SESSDATA,我为了省事这么写了。
格式化得到a=1,b=2,c=3格式的cookie信息,然后参见上一章完成目标即可。
https://blogs.qudange.top/p/2024-07-13-android_tasker_ai_summary/
。。玩笑归玩笑,绝区零真的是动作游戏爱好者福音吧。本人爱丽丝摇篮45小时,魔女复仇之夜82小时,棘罪修女60小时,哥特修女勇闯恶魔城一71小时,哈奇娜怪异谭79小时,阿尔卑斯与危险森林67小时,深海姐妹42小时,银白猎人91小时,夏哈塔遭难的一天88小时,圣骑士莉卡79小时,悲剧森林34小时,乱斗少女53小时,wings of blood 55小时,深渊之魂62小群青的魔女魔女49小时,玉莲之剑21小时,永恒的欠损79小时很多老动作游戏也都玩过了,只有绝区零能给我一种刚接触动作游戏时的感动。
刚刚第一次用买的电动充气泵给自行车打气,打完一个胎的时候就发现气嘴很烫,当时比较着急,就硬捏着拆下来给第二个打了,结果现在突然发现食指上烫出了一个水泡,恐怖。。

载入中
已到底部
没有可加载的页面
回复